
Deep Dive into Linux NFS Debugging: Kernel Analysis, Troubleshooting, and Performance Tuning
Introduction: The Complexity of Network File Systems in Modern Linux Environments
In the constantly evolving landscape of **Linux server news** and infrastructure, the Network File System (NFS) remains a cornerstone of shared storage architecture. Despite its age, NFS is critical for everything from **Linux DevOps news** workflows to high-availability clusters in **Kubernetes Linux news**. However, as many seasoned system administrators and kernel developers know, NFS can be a source of complex, elusive bugs that manifest as system hangs, high load averages, or silent data corruption.
Recent discussions in the **Linux kernel news** community have highlighted the difficulty of tracking down race conditions and stale file handle errors within the NFS subsystem. Unlike local filesystems like **ext4 news**, **Btrfs news**, or **ZFS news**, NFS relies heavily on the network stack, the Remote Procedure Call (RPC) mechanism, and the Virtual File System (VFS) layer’s ability to cache attributes correctly. When these components fall out of sync, diagnosing the issue requires more than just checking logs; it demands a deep understanding of kernel internals.
This article provides a comprehensive technical analysis of NFS debugging on Linux. We will explore how to hunt down kernel-level bugs, analyze **Linux networking news** related to latency, and implement robust configurations. Whether you are managing **Red Hat news** enterprise servers, **Debian news** clusters, or bleeding-edge **Arch Linux news** workstations, understanding the depths of NFS is essential for maintaining system stability.
Section 1: Core Concepts of NFS and Kernel Interactions
To effectively debug NFS, one must understand how the Linux kernel handles remote filesystem operations. When a user application interacts with a file on an NFS mount, the request passes through the System Call Interface to the VFS. The VFS abstracts the underlying filesystem, allowing applications to treat remote files exactly like local ones.
However, the kernel’s NFS client module must translate these VFS operations into RPC calls sent over the network (usually TCP) to the server. This introduces several layers of complexity involving **Linux memory management news** (page cache) and **Linux networking news** (congestion control).
The Role of Attribute Caching
A common source of confusion and bugs is Attribute Caching. The kernel caches file attributes (metadata like size, permissions, and modification time) to reduce network chatter. Parameters like `acregmin` and `acregmax` control how long these attributes are trusted. If the kernel uses stale cache data, applications might try to read past the end of a file or write to a file that has been locked by another client.
Below is a practical example of setting up an NFS export with specific options to mitigate some of these issues, relevant for **Linux administration news** and setup.
# /etc/exports configuration example
# Best practices for a stable NFSv4 server setup on Rocky Linux or AlmaLinux
# Path to export Allowed IPs(Options)
/srv/nfs/share 192.168.10.0/24(rw,sync,no_root_squash,no_subtree_check,fsid=0)
# Explanation of critical flags:
# sync: Forces the server to reply to requests only after changes
# have been committed to stable storage. This is critical for
# data integrity, though it impacts Linux performance news.
# no_subtree_check: Disables subtree checking, which improves reliability
# when a file is renamed while open.
# fsid=0: Required for NFSv4 root exports.
# Applying the configuration
exportfs -arv
# Verifying the active exports
exportfs -sIn **Linux virtualization news**, particularly with **KVM news** or **Proxmox news**, using `sync` is vital to prevent VM corruption during power loss, even if it lowers raw throughput.
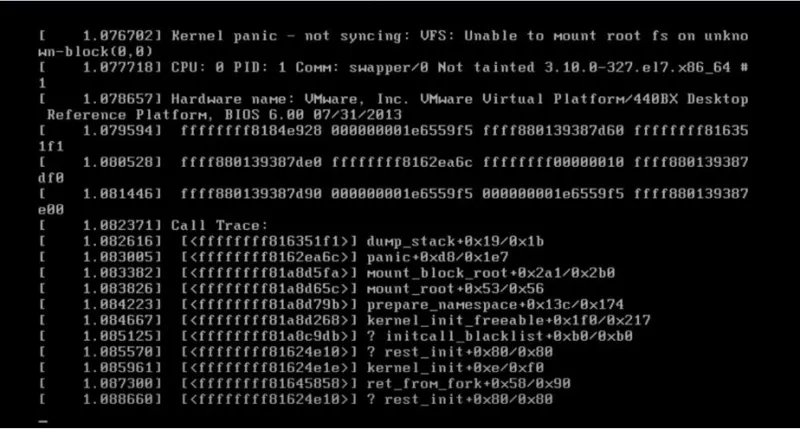
Section 2: Hunting the Bug – Tools and Implementation
When an NFS mount hangs, processes often enter the dreaded “D-state” (Uninterruptible Sleep). This contributes to high load averages and cannot be killed with `kill -9`. This usually happens because the kernel is waiting for an I/O response that never comes. Troubleshooting this requires peering into the RPC layer.
Using rpcdebug and Tracepoints
Standard tools like `top` or `htop` (staples of **Linux processes news**) only show the symptom. To see the cause, we need to enable kernel debug logging for the NFS module. This is a technique often discussed in **Linux troubleshooting news**.
The `rpcdebug` utility allows you to set bitmasks in the kernel to log specific NFS and RPC events to the syslog (viewable via `dmesg` or `journalctl`).
#!/bin/bash
# Script to enable deep NFS debugging
# WARNING: This generates massive logs. Use with caution in production.
# Check current debug flags
rpcdebug -m nfs -s
rpcdebug -m rpc -s
# Enable debugging for NFS VFS operations and Proc calls
echo "Enabling NFS kernel debugging..."
rpcdebug -m nfs -s vfs proc
# Enable debugging for RPC socket and transport
echo "Enabling RPC kernel debugging..."
rpcdebug -m rpc -s trans socket
# Tail the kernel ring buffer to see the output
# You might see messages about "slot table" or "xprt" (transport)
dmesg -w | grep -i "nfs"
# DISABLE debugging immediately after capturing data
# rpcdebug -m nfs -c all
# rpcdebug -m rpc -c allAnalyzing NFS Statistics with Python
For a broader view of **Linux monitoring news**, parsing `/proc/self/mountstats` provides granular details about RPC calls, retransmissions, and latency. While tools like `nfsstat` exist, writing a custom parser allows for integration into **Prometheus news** or **Grafana news** dashboards.
Here is a Python script that parses NFS mount statistics to identify high latency or packet loss, which are often precursors to kernel bugs or network failures.
import re
def parse_nfs_stats(mount_point):
"""
Parses /proc/self/mountstats to find retransmission rates
and operation counts for a specific mount.
"""
stats_file = '/proc/self/mountstats'
mount_data = {}
try:
with open(stats_file, 'r') as f:
content = f.read()
# Split by device entry
devices = content.split('device ')
for dev in devices:
if mount_point not in dev:
continue
# Extract basic RPC stats
# Look for the "RPC iostats version" block
if 'RPC iostats' in dev:
lines = dev.split('\n')
for line in lines:
if line.strip().startswith('xprt:'):
# Format: xprt: protocol port bind_count connect_count ...
parts = line.split()
mount_data['protocol'] = parts[1]
mount_data['connect_count'] = int(parts[4])
mount_data['idle_time'] = int(parts[6])
if line.strip().startswith('per-op statistics'):
# This indicates the start of operation breakdown
mount_data['ops_captured'] = True
return mount_data
except FileNotFoundError:
print("Error: /proc/self/mountstats not found. Is this a Linux system?")
return None
except Exception as e:
print(f"An error occurred: {e}")
return None
if __name__ == "__main__":
# Example usage
target_mount = "/mnt/nfs_share"
stats = parse_nfs_stats(target_mount)
if stats:
print(f"--- NFS Stats for {target_mount} ---")
print(f"Protocol: {stats.get('protocol', 'Unknown')}")
print(f"Connection Count: {stats.get('connect_count', 0)}")
print(f"Idle Time (seconds): {stats.get('idle_time', 0)}")
if stats.get('connect_count', 0) > 100:
print("WARNING: High reconnection count detected. Check network stability.")
else:
print("Mount point not found in stats.")Section 3: Advanced Techniques and Race Conditions
In the realm of **Linux kernel news**, some of the most fascinating NFS bugs involve race conditions between the client’s page cache and the server’s file state. A classic scenario involves “close-to-open” consistency. NFS guarantees that when a file is closed by one client, the changes are flushed to the server. However, if another client opens the file before the flush completes, or if the network drops the commit packet, data corruption can occur.
The “Silly Rename” Problem
NFS cannot delete a file that is still open by a process (unlike local POSIX filesystems where the inode persists until the file descriptor is closed). To emulate POSIX behavior, the NFS client renames the file to `.nfsXXXX` (a “silly rename”) and deletes it only when the file is closed. If the client crashes before closing, these files persist, filling up storage—a common topic in **Linux storage news**.
Debugging Locking with C
File locking (flock/fcntl) over NFS is handled by the NLM (Network Lock Manager) in NFSv3 or built-in to NFSv4. Locking bugs are notorious in **Linux database news** scenarios (like **SQLite** over NFS, which is generally discouraged).

Below is a C program designed to test file locking capabilities on an NFS mount. This is useful for validating if your **Linux clustering news** setup (like **Pacemaker news** or **Corosync news**) handles shared locks correctly.
#include
#include
#include
#include
#include
#include
// Compile with: gcc nfs_lock_test.c -o nfs_lock_test
// Usage: ./nfs_lock_test /mnt/nfs/testfile
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s \n", argv[0]);
return 1;
}
const char *filename = argv[1];
int fd;
struct flock fl;
printf("Attempting to open %s...\n", filename);
fd = open(filename, O_RDWR | O_CREAT, 0666);
if (fd == -1) {
perror("open");
return 1;
}
// Initialize the flock structure
memset(&fl, 0, sizeof(fl));
fl.l_type = F_WRLCK; // Write lock
fl.l_whence = SEEK_SET; // Start of file
fl.l_start = 0;
fl.l_len = 0; // Lock whole file
printf("Attempting to acquire exclusive write lock (F_WRLCK)...\n");
// F_SETLKW waits for the lock if it's held by another process
if (fcntl(fd, F_SETLKW, &fl) == -1) {
perror("fcntl");
close(fd);
return 1;
}
printf("Lock acquired! Holding for 10 seconds. Try running this on another client now.\n");
sleep(10);
// Release the lock
fl.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &fl) == -1) {
perror("fcntl unlock");
} else {
printf("Lock released.\n");
}
close(fd);
return 0;
} If this program hangs indefinitely on `fcntl` without a valid reason, you may be facing a split-brain scenario in the locking daemon or a firewall issue blocking the NLM ports (relevant to **iptables news** and **nftables news**).
Section 4: Best Practices and Optimization Strategies
To avoid being the subject of the next viral **Linux engineering blog post**, adhering to best practices is crucial. Whether you are running **Ubuntu news** LTS versions or **Fedora news** releases, the configuration of the NFS client is just as important as the server.
NFSv3 vs. NFSv4
NFSv4 significantly simplifies firewall configuration by using a single TCP port (2049), whereas NFSv3 requires `rpcbind`, `mountd`, and `nlockmgr` running on random ports. For modern **Linux security news** and **Linux firewall news**, NFSv4 is the standard. It also introduces statefulness, which helps in tracking open files and locks.
Automating Configuration with Ansible
In the world of **Linux automation news**, manual edits to `/etc/fstab` are prone to error. Using **Ansible news** or **Terraform Linux news** ensures consistency. Here is an Ansible task that implements mount options optimized for performance and resilience.
---
- name: Configure Robust NFS Mounts
hosts: nfs_clients
become: yes
tasks:
- name: Ensure NFS utils are installed
package:
name: "{{ item }}"
state: present
loop:
- nfs-utils # RedHat/CentOS family
# - nfs-common # Debian/Ubuntu family (uncomment based on OS)
- name: Mount the shared application data
ansible.posix.mount:
path: /var/www/html/shared
src: 10.10.0.5:/exports/web_data
fstype: nfs
opts: "rw,hard,intr,rsize=1048576,wsize=1048576,timeo=600,retrans=2,vers=4.2"
state: mounted
# Key Options Explained:
# hard: The client will keep trying indefinitely if the server goes down.
# 'soft' can lead to data corruption.
# intr: Allows the user to interrupt (CTRL+C) a hung process waiting on NFS.
# rsize/wsize: 1MB buffers for modern high-bandwidth networks (10GbE+).
# vers=4.2: Forces the use of modern NFSv4.2 features like server-side copy.Network Considerations
NFS is intolerant of packet loss. **Linux networking news** often highlights the importance of Jumbo Frames (MTU 9000) for storage traffic. Ensure your switches and network interface cards (NICs) are configured correctly. Using **ethtool** to check ring buffer sizes is a standard step in **Linux performance news**.
Furthermore, in **Linux cloud news** environments like **AWS Linux news** or **Google Cloud Linux news**, underlying storage latency can fluctuate. Monitoring tools like **Prometheus news** should be configured to alert on high NFS latency, not just server up/down status.
Conclusion
Debugging NFS bugs in the Linux kernel is a rite of passage for many system engineers. It bridges the gap between **Linux networking news**, **Linux storage news**, and **Linux kernel news**. From understanding the VFS layer’s interaction with RPC to using tools like `rpcdebug` and custom Python parsers, the path to resolution requires a methodical approach.
As distributions like **Rocky Linux news**, **Linux Mint news**, and **openSUSE news** continue to update their kernels, staying informed about the latest NFS patches is vital. The shift toward NFSv4.2 and pNFS (Parallel NFS) promises better performance for **Linux clustering news** and **Linux AI/ML** workloads, but it also brings new complexity.
By implementing the code examples provided—monitoring stats, verifying locks, and automating configuration—you can transform a fragile shared storage system into a robust enterprise asset. Remember, in the world of Linux, the logs always tell the story; you just need the right tools to read them.


