
When Security Tools Cause System Instability: A Proactive Guide for Rocky Linux Administrators
The Paradox of Protection: When Security Agents Destabilize Enterprise Linux
In the world of enterprise computing, stability is paramount. Distributions like Rocky Linux, AlmaLinux, and other derivatives of the Red Hat Enterprise Linux ecosystem are chosen specifically for their predictability, long-term support, and robust performance. System administrators build critical infrastructure on this foundation, trusting it to run reliably for years. However, a growing challenge threatens this stability from an unexpected direction: the very security tools designed to protect these systems. Modern Endpoint Detection and Response (EDR), antivirus, and monitoring agents often require deep system integration, frequently operating as kernel modules. While powerful, this privileged position means a single flawed update can bring a server, or an entire fleet, to its knees. This article explores the risks associated with third-party kernel-level software on Rocky Linux and provides a comprehensive, proactive strategy for system administrators to mitigate these threats, ensuring that their quest for security doesn’t inadvertently sabotage stability.
Understanding the Kernel-Space Risk on Your Linux Server
To effectively manage the risk, it’s crucial to understand why these agents are so powerful and, consequently, so potentially dangerous. The Linux kernel is the core of the operating system, managing hardware, memory, and processes. Code running in “kernel-space” has privileged access, which is necessary for tasks like intercepting system calls, monitoring network traffic at a low level, and scanning file I/O for threats. This is in contrast to “user-space,” where standard applications run with limited privileges. When a third-party, often closed-source, module is loaded into the kernel, you are placing immense trust in that vendor’s code quality and testing processes.
Identifying and Inspecting Kernel Modules
The first step in any risk assessment is discovery. You need to know what third-party modules are running on your system. The lsmod command provides a list of all currently loaded kernel modules. You can combine it with grep to search for modules from a specific vendor.
Once a module is identified, the modinfo command can provide more details, including the author, description, and the file path to the module itself. This information is vital for tracking and documentation.
# List all loaded kernel modules and filter for a hypothetical agent named 'secagent'
lsmod | grep secagent
# Example output:
# secagent_core 1048576 2
# secagent_netfilter 65536 1 secagent_core
# secagent_fs 131072 1 secagent_core
# Get detailed information about a specific module
modinfo secagent_core
# Example output:
# filename: /lib/modules/4.18.0-513.11.1.el8_9.x86_64/extra/secagent_core.ko
# version: 1.2.3-45
# license: Proprietary
# author: Security Vendor Inc.
# description: Core security agent module.
# srcversion: A1B2C3D4E5F6G7H8I9J0
# depends:
# name: secagent_core
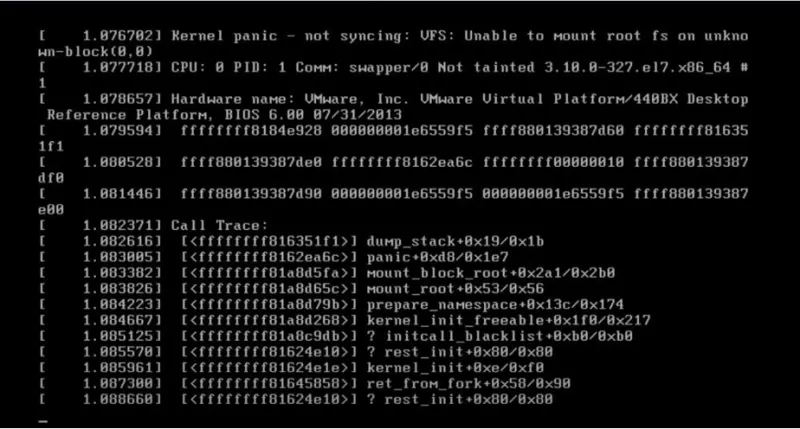
# vermagic: 4.18.0-513.11.1.el8_9.x86_64 SMP mod_unload modversionsThe “vermagic” string is particularly important. It ensures that a module is compiled for the exact kernel version it’s being loaded into. A mismatch here is a common cause of system panics, which is why agent updates must be perfectly synchronized with kernel updates from your distribution—a process that can easily fail with automatic, forced updates.
A Strategy of Control: Staging, Testing, and Version Pinning
Relying solely on a vendor’s quality assurance is a recipe for disaster. A robust internal testing and deployment strategy is non-negotiable for any critical system. The core principle is to prevent untested code from ever reaching your production environment.
Implementing Version Locking with DNF
One of the most powerful tools in a Rocky Linux administrator’s arsenal is the DNF package manager’s versionlock plugin. This plugin allows you to “pin” a package to its current version, preventing dnf update from automatically upgrading it. This gives you explicit control over when a sensitive component, like a security agent, is updated.
First, ensure the plugin is installed:
sudo dnf install 'dnf-command(versionlock)'Once a security agent is installed and verified to be stable in your testing environment, you can lock its version before deploying to production. This ensures that a vendor can’t push an update without your explicit action to unlock, update, and re-lock the package.
# Assume the security agent package is named 'security-agent'
# First, find the exact version installed
# dnf list installed security-agent
# Lock the package to its current version
sudo dnf versionlock add security-agent
# To see all locks in place:
# sudo dnf versionlock list
# When you are ready to update after thorough testing:
# 1. Remove the lock
# sudo dnf versionlock delete security-agent
# 2. Perform the update
# sudo dnf update security-agent
# 3. Add the lock back
# sudo dnf versionlock add security-agentAutomating Controlled Rollouts with Ansible
Managing version locks manually across a fleet of servers is inefficient and error-prone. This is where configuration management tools like Ansible excel. You can create a playbook that ensures a specific, tested version of the agent is installed and that the version lock is in place. This codifies your policy and makes deployments repeatable and auditable. This approach is a cornerstone of modern Linux DevOps and Linux administration news.
---
- name: Manage Security Agent Installation
hosts: all
become: yes
vars:
agent_version: "1.2.3-45.el8"
agent_package: "security-agent"
tasks:
- name: Ensure DNF versionlock plugin is installed
dnf:
name: 'dnf-command(versionlock)'
state: present
- name: Install the specific version of the security agent
dnf:
name: "{{ agent_package }}-{{ agent_version }}"
state: present
allow_downgrade: yes
- name: Lock the security agent version
command: "dnf versionlock add {{ agent_package }}"
args:
# This ensures the command only runs if the lock isn't already there
creates: "/etc/dnf/plugins/versionlock.list"
# A more robust check would grep the lock file itselfThis playbook ensures that every server in your inventory is running the exact version of the agent you have certified, preventing unexpected updates from destabilizing your environment.
Advanced Monitoring and Rapid Incident Response
Even with rigorous testing, problems can occur. The key is to detect them quickly and have a plan to respond. Subtle issues, like memory leaks or performance degradation, might not be caught in pre-production testing. This requires a deeper level of monitoring in your production environment.

Proactive Kernel Log Analysis
The kernel is very vocal when it’s unhappy. Tainted kernels, call traces, and error messages are logged centrally via journald. A system administrator should be actively monitoring these logs for signs of trouble. You can use journalctl to filter for kernel messages and specific priority levels.
# Show all kernel messages from the current boot with priority 'error' or higher
journalctl -k -p err..alert
# Follow the kernel log in real-time for troubleshooting
journalctl -fk
# Search for messages related to a specific kernel module
journalctl -k | grep 'secagent'Setting up automated alerts for kernel error messages or “taint” notifications can provide an early warning that a module is misbehaving, long before a full system crash occurs. This is a critical part of any Linux monitoring strategy.
Leveraging eBPF for Deeper Insight
For more advanced and safer introspection, modern Linux kernels offer the extended Berkeley Packet Filter (eBPF). eBPF allows you to run sandboxed programs within the kernel itself, enabling incredibly powerful and low-overhead observability. Tools built on eBPF, like those in the BCC (BPF Compiler Collection) or `bpftrace`, can be used to trace system calls, kernel function calls, and network events related to a specific process or kernel module without the risk of crashing the system. This is an invaluable tool for diagnosing performance issues or unexpected behavior caused by a third-party agent.
While a deep dive into eBPF is beyond this article’s scope, even simple one-liners can provide immense value. For example, you could use `bpftrace` to see which kernel functions within a specific module are being called most frequently, helping you pinpoint a source of high CPU usage.
Best Practices for a Resilient Infrastructure
Beyond specific commands and tools, a successful strategy relies on a holistic approach to managing third-party software on your Rocky Linux systems.
- Thorough Vendor Vetting: Before deploying any agent, ask the vendor hard questions. What is their QA process? How do they test against new kernel versions released in Rocky Linux news and Red Hat news? What is their emergency rollback procedure? A transparent vendor is a better partner.
- Embrace “Configuration as Code”: Use tools like Ansible, Puppet, or SaltStack to manage the configuration of your security agents. This prevents configuration drift and ensures that every system is in a known, desired state.
- Automate Health Checks: After any update—whether it’s the OS kernel or a security agent—automated tests should run to verify that your critical applications are still functioning correctly. This could be a simple script that checks an application’s API endpoint or database connectivity.
- Maintain a Rollback Plan: Always have a clear, documented, and tested procedure for removing or downgrading a faulty agent. For virtualized environments, this might involve reverting to a pre-update snapshot. For bare-metal, it means having the previous version of the RPM package available in a local repository.
Conclusion: Reclaiming Control and Ensuring Stability
The stability of enterprise distributions like Rocky Linux is not an accident; it’s the result of meticulous engineering and conservative update cycles. However, this stability can be easily compromised by third-party software that operates with the highest levels of privilege. The recent challenges seen across the Linux ecosystem, from Debian news to Ubuntu news, highlight that this is a universal problem. For administrators, the path forward is not to reject these security tools, but to manage them with discipline and skepticism. By implementing a robust strategy of version control, automated testing in isolated environments, and deep, proactive monitoring, you can harness the protective power of these agents without sacrificing the reliability that is the hallmark of Rocky Linux. True system resilience comes from acknowledging that every piece of software, especially security software, is a potential point of failure and planning accordingly.


