
Fortifying Your Kubernetes Cluster: A Deep Dive into Secure Logging on Linux
The Double-Edged Sword of Observability in Kubernetes
In the dynamic world of cloud-native computing, Kubernetes has become the de facto standard for orchestrating containerized applications on Linux. From major distributions like Ubuntu and Debian to enterprise-grade systems like Red Hat Enterprise Linux and SUSE Linux Enterprise Server, Kubernetes provides a robust foundation for modern infrastructure. A cornerstone of managing these complex environments is observability—the ability to understand the internal state of a system from its external outputs. This is achieved through the “three pillars”: metrics, traces, and, most fundamentally, logs. Logging in Kubernetes is not just a feature; it’s a critical lifeline for debugging, monitoring, and security analysis. However, the very tools that grant us this deep visibility can, if misconfigured, become significant security liabilities. This is a recurring theme in recent Kubernetes Linux news and Linux security news.
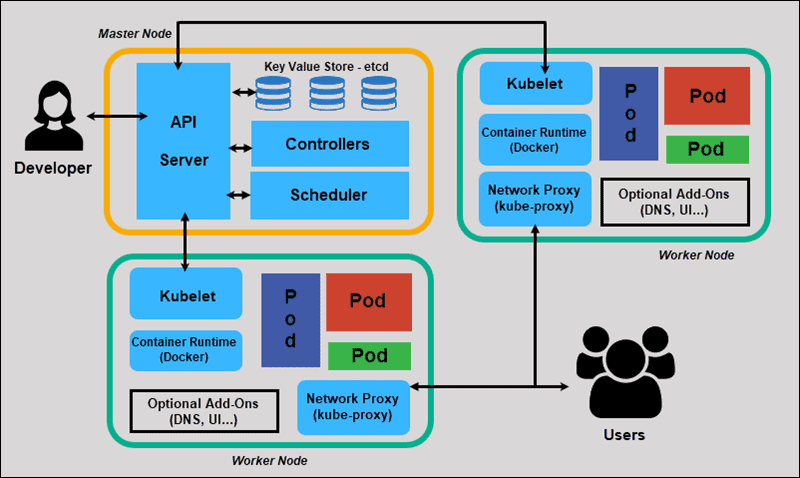
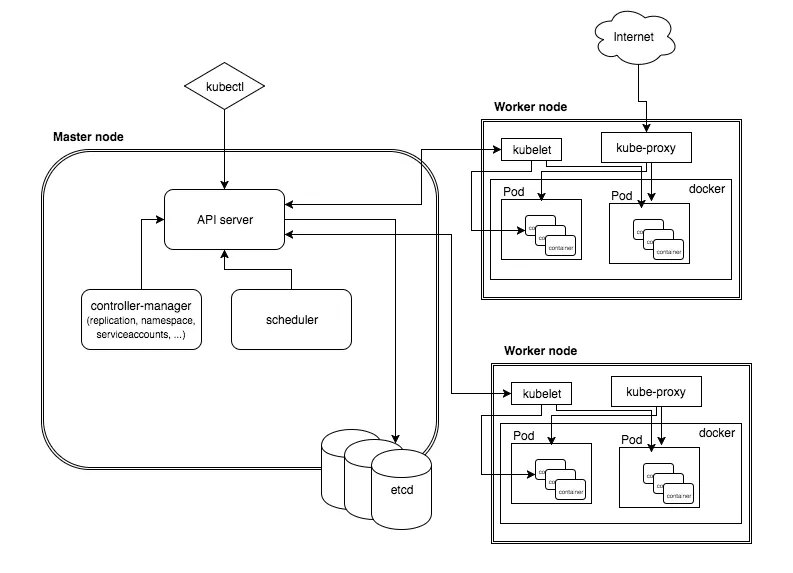
Logging agents, often deployed as a DaemonSet across every node in a cluster, typically require privileged access to read container logs from the host filesystem. This privileged position makes them a high-value target for attackers. A vulnerability in a widely-used logging agent could potentially expose sensitive log data, allow for lateral movement within the cluster, or even lead to a full node compromise. Therefore, understanding how to implement a secure, resilient, and efficient logging pipeline is no longer an operational best practice—it’s a critical security requirement for any production-grade Kubernetes deployment running on Linux.
Anatomy of a Modern Kubernetes Logging Pipeline
Before diving into security, it’s essential to understand the typical architecture of a logging pipeline in a Kubernetes environment. The goal is to collect logs from all applications running in pods, enrich them with valuable metadata (like pod name, namespace, and labels), and forward them to a centralized storage and analysis backend. This process usually involves several distinct stages and specialized tools.
Core Components and Data Flow
- Log Generation: Applications running inside containers write logs to standard output (
stdout) and standard error (stderr). The container runtime (like containerd or CRI-O) redirects these streams to log files on the host node, typically within/var/log/pods/. - Log Collection: A logging agent is deployed as a Kubernetes DaemonSet. This ensures that an instance of the agent runs on every single node in the cluster. This agent’s primary job is to find, tail, and parse the container log files on its host node.
- Processing and Forwarding: The agent parses the raw log lines, enriches them with Kubernetes metadata by querying the Kubernetes API, and buffers them for efficient forwarding.
- Aggregation and Storage: The processed logs are sent over the network to a centralized aggregation service or a long-term storage backend like Elasticsearch, Loki, or a cloud provider’s logging service.
A very popular and powerful tool for the collection stage is Fluent Bit. It’s a lightweight, high-performance log processor and forwarder, written in C, making it ideal for the resource-constrained environments of a node agent. Its pluggable architecture allows it to integrate with a vast ecosystem of inputs and outputs. For many organizations, the latest Linux DevOps news involves optimizing these pipelines for performance and cost.
Example: A Basic Fluent Bit DaemonSet
Here is a simplified YAML manifest for deploying Fluent Bit as a DaemonSet. This configuration mounts the necessary host directories and sets up a basic input to tail all container logs.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: kube-system
labels:
k8s-app: fluent-bit-logging
spec:
selector:
matchLabels:
k8s-app: fluent-bit-logging
template:
metadata:
labels:
k8s-app: fluent-bit-logging
spec:
serviceAccountName: fluent-bit
terminationGracePeriodSeconds: 10
containers:
- name: fluent-bit
image: fluent/fluent-bit:2.1.10
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: true
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: fluent-bit-config
mountPath: /fluent-bit/etc/
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: fluent-bit-config
configMap:
name: fluent-bit-configThis manifest lays the groundwork, but it crucially omits security configurations, which we will address next.
Implementing Least Privilege with RBAC
One of the most common security pitfalls in Kubernetes is granting excessive permissions to system components. A logging agent needs to interact with the Kubernetes API server to retrieve metadata about pods and namespaces. Without proper Role-Based Access Control (RBAC), a compromised agent pod could potentially read secrets, modify deployments, or delete resources across the entire cluster. Adhering to the principle of least privilege is paramount.
Creating a Dedicated Service Account and Roles
Instead of running the agent with the default service account, you must create a dedicated ServiceAccount, a ClusterRole that defines the minimum necessary permissions, and a ClusterRoleBinding to link them together.
The agent needs to be able to get, list, and watch pods, namespaces, and sometimes nodes across the cluster to enrich the logs with context. It should not have permission to modify or delete anything.
Practical RBAC Configuration for Fluent Bit
The following YAML manifest provides a secure, minimal set of permissions for a Fluent Bit DaemonSet. This is a critical piece of Linux administration news for any Kubernetes administrator.
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluent-bit
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluent-bit-read
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
- pods/logs
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluent-bit-read
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: fluent-bit-read
subjects:
- kind: ServiceAccount
name: fluent-bit
namespace: kube-systemBy applying this configuration, you ensure that even if an attacker gains control of the Fluent Bit container, their ability to interact with the Kubernetes API is strictly limited to read-only operations on specific resources, dramatically reducing the blast radius of a potential breach. This aligns with modern Zero Trust principles discussed in Linux server news and security forums.
Advanced Hardening: Network Policies and Secure Configuration
Beyond RBAC, a defense-in-depth strategy requires further hardening at the network and application layers. We must assume that a component *could* be compromised and put controls in place to limit the damage.
Restricting Egress with Network Policies
By default, pods in Kubernetes can send traffic to any other pod in the cluster and to the internet. A compromised logging agent could be used to exfiltrate data or scan the internal network. Kubernetes NetworkPolicy objects allow you to define firewall rules at the pod level.
You should create a policy that explicitly allows the Fluent Bit pods to send traffic *only* to the intended log aggregation service (e.g., a Fluentd or Loki service) and the Kubernetes API server. All other egress traffic should be denied.
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-fluent-bit-egress
namespace: kube-system
spec:
podSelector:
matchLabels:
k8s-app: fluent-bit-logging
policyTypes:
- Egress
egress:
# Allow DNS resolution
- to:
- namespaceSelector: {}
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- protocol: UDP
port: 53
# Allow communication with the Kubernetes API server
- to:
- ipBlock:
cidr: 10.96.0.1/32 # Replace with your API server IP if different
ports:
- protocol: TCP
port: 443
# Allow communication with the log aggregator (e.g., Loki)
- to:
- namespaceSelector:
matchLabels:
name: monitoring
podSelector:
matchLabels:
app: loki
ports:
- protocol: TCP
port: 3100Securing the Data in Transit
Log data often contains sensitive information. It is crucial to encrypt this data as it travels from the collection agent on the node to the central aggregator. Most modern logging tools support TLS for this purpose. When configuring your agent’s output, always enable TLS and, for maximum security, verify the server’s certificate.
Here is an example snippet from a fluent-bit.conf file showing how to configure a secure forward output to a Fluentd aggregator.
[OUTPUT]
Name forward
Match *
Host fluentd.logging.svc.cluster.local
Port 24224
tls On
tls.verify On
tls.ca_file /fluent-bit/ssl/ca.crt
Shared_Key your_secure_shared_key # Use a Kubernetes secret for this!Notice the use of tls On and tls.verify On. The CA certificate and any shared keys should be mounted into the pod using Kubernetes Secrets, not hardcoded in a ConfigMap or the container image. This is a fundamental practice covered in many Linux certification news articles and training materials.
Best Practices for a Resilient and Observable Logging Stack
A secure logging pipeline is also a reliable one. Downtime in your observability stack can leave you blind during a critical production incident. Here are some best practices to ensure your logging infrastructure is robust and maintainable.
Monitor the Monitors
Your logging pipeline is a critical piece of infrastructure and must be monitored itself. Fluent Bit and Fluentd expose detailed metrics in the Prometheus format.
- Scrape Metrics: Use Prometheus to scrape metrics from your logging agents. Key metrics to watch include buffer usage, number of retries, output errors, and records processed.
- Create Dashboards: Use Grafana to build dashboards that visualize the health of your logging pipeline. This can help you spot issues like a sudden drop in log volume or a spike in parsing errors.
- Set Up Alerts: Configure alerts in Alertmanager to notify you immediately if a logging agent stops responding or if error rates exceed a certain threshold. The latest Prometheus news and Grafana news often highlight new features for improving this kind of meta-monitoring.
Resource Management
Logging agents can consume significant CPU and memory, especially under heavy log load.
- Set Requests and Limits: Always define CPU and memory requests and limits for your logging agent pods. This prevents them from starving other applications on the node or being OOMKilled (Out Of Memory Killed) unexpectedly.
- Tune Buffering: Configure buffering settings carefully. Storing too much in memory can lead to memory pressure, while storing on the filesystem can impact disk I/O. Find a balance that works for your workload and node resources.
Stay Updated
The open-source landscape, especially around security, moves quickly. News of vulnerabilities in core infrastructure components is common.
- Patch Regularly: Subscribe to security mailing lists and announcements for all components in your stack (Fluent Bit, Fluentd, Elasticsearch, etc.). Apply security patches as soon as they are released.
- Use Scanners: Integrate container image vulnerability scanning into your CI/CD pipeline. Tools like Trivy, Grype, or Clair can automatically scan your logging agent images for known CVEs before they are deployed. This is a key topic in Linux CI/CD news.
Conclusion: From Liability to Asset
In the complex, distributed world of Kubernetes on Linux, a robust logging pipeline is indispensable. It transforms cryptic failures into actionable insights and provides the audit trail necessary for security and compliance. However, this power comes with responsibility. As we’ve seen, the components that provide this visibility operate in a privileged position, making them a prime target. The latest Linux news continually reminds us that security cannot be an afterthought.
By adopting a defense-in-depth approach—starting with the principle of least privilege using RBAC, isolating network traffic with Network Policies, encrypting data in transit with TLS, and diligently monitoring the health of the pipeline itself—you can transform your logging infrastructure from a potential liability into a hardened, reliable, and secure operational asset. The next step is to review your own cluster’s logging setup. Audit the permissions of your agents, check for unencrypted traffic, and ensure you have monitoring and alerting in place. In the ever-evolving landscape of cloud-native security, proactive hardening is the key to staying ahead of threats.


