
Mastering Log Management: A Deep Dive into the ELK Stack on Linux
In today’s complex IT landscape, managing logs is no longer a simple task of tailing a file on a single server. Modern infrastructure, driven by microservices, containers, and distributed systems, generates a torrent of log data across countless endpoints. For Linux administrators and DevOps engineers, trying to manually correlate events, troubleshoot issues, or detect security threats across this decentralized chaos is an impossible challenge. This is where centralized logging and analysis platforms become indispensable. The ELK Stack—now officially known as the Elastic Stack—has emerged as the de facto open-source solution for this problem, providing a powerful, scalable, and flexible toolkit for wrangling log data on any Linux distribution, from Ubuntu and Debian to CentOS and the entire Red Hat family.
The stack’s power lies in its three core components: Elasticsearch for searching and analytics, Logstash for server-side processing, and Kibana for visualization. Together, they create a robust pipeline that can ingest, transform, and display data from virtually any source. This article provides a comprehensive technical guide to leveraging the ELK Stack for effective log management in a modern Linux environment, covering everything from core concepts and practical implementation to advanced techniques and optimization best practices. Whether you’re managing a fleet of Linux servers, a Kubernetes cluster, or a simple web application, this guide will equip you with the knowledge to turn your scattered log files into actionable insights.
The Anatomy of the ELK Stack: Elasticsearch, Logstash, and Kibana
Before diving into implementation, it’s crucial to understand the role each component plays in the data pipeline. While they are designed to work together seamlessly, each is a powerful project in its own right, contributing to the latest in Linux observability news.
Elasticsearch: The Search and Analytics Engine
At the heart of the stack is Elasticsearch, a distributed, RESTful search and analytics engine built on Apache Lucene. Its primary function is to store data in a way that allows for incredibly fast searches and complex aggregations. Data is stored as JSON documents in indices, which are roughly analogous to tables in a relational database. Its distributed nature means it can scale horizontally by adding more nodes to a cluster, making it suitable for handling petabytes of data. This scalability is a frequent topic in Linux performance news, as it allows organizations to grow their monitoring capabilities without hitting a ceiling.
Logstash: The Data Processing Pipeline
Logstash is the workhorse of the stack, responsible for data ingestion and transformation. It acts as a server-side data processing pipeline that can receive data from a multitude of sources simultaneously. A Logstash pipeline has three stages: inputs, filters, and outputs.
- Inputs: Generate events. They can read from files, receive data over a network (TCP, UDP, HTTP), or connect to services like Kafka or Redis.
- Filters: The most powerful feature of Logstash. Filters allow you to parse, enrich, and transform the data as it passes through. The most common filter is “grok,” which uses regular expressions to parse unstructured log data into structured fields.
- Outputs: Send the processed events to their destination. The most common output is, of course, Elasticsearch, but Logstash can also send data to other systems, write to files, or trigger alerts.
# Example logstash.conf for processing system logs
# This configuration is relevant for anyone following systemd news or journalctl news,
# as it can be adapted to ingest logs directly from the systemd journal.
input {
file {
path => "/var/log/syslog"
start_position => "beginning"
sincedb_path => "/dev/null" # For demonstration purposes
}
}
filter {
# Grok is used to parse unstructured syslog messages
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
}
# Date filter to use the log's own timestamp
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "syslog-%{+YYYY.MM.dd}"
}
# For debugging purposes, also output to the console
stdout { codec => rubydebug }
}Kibana: The Visualization Layer
Kibana is the window into your Elasticsearch data. It’s a powerful and flexible web-based user interface that allows you to explore, visualize, and build dashboards on top of your logs. With Kibana, you can run ad-hoc searches, create line graphs, pie charts, heat maps, and geographical maps, and combine them into real-time dashboards. This is invaluable for everything from monitoring Linux web servers news by visualizing Nginx traffic to tracking security events relevant to Linux security news.
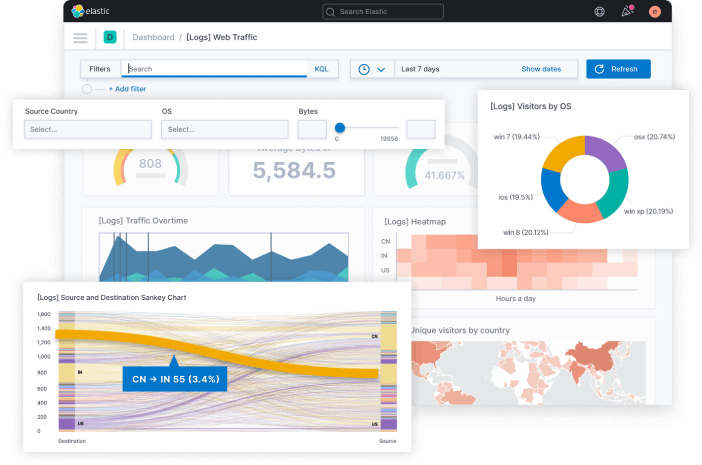
The Rise of Beats: Lightweight Data Shippers
While Logstash is powerful, its resource footprint (running on the JVM) can be too heavy for small edge devices or resource-constrained servers. To solve this, Elastic introduced Beats, a family of lightweight, single-purpose data shippers. The most common one for log management is Filebeat. It’s designed to be installed on client servers to tail log files and forward them securely and reliably to either Logstash for further processing or directly to Elasticsearch. This approach is central to modern Linux DevOps news and best practices.
Setting Up Your First ELK Pipeline on Linux
Deploying the ELK Stack can be done on nearly any Linux distribution. The process is well-documented for systems using apt news (Debian, Ubuntu, Linux Mint) and those using dnf news or yum news (Fedora, CentOS, Rocky Linux). Here, we’ll walk through a typical setup for ingesting Nginx access logs, a common task for any Linux administrator.
Installation and Configuration
First, you would install Elasticsearch, Logstash, and Kibana on a central monitoring server. On a Debian or Ubuntu system, this involves adding the Elastic APT repository and then installing the packages. Once installed, you need to configure each component. For Elasticsearch, you’ll typically set network host settings in /etc/elasticsearch/elasticsearch.yml. For Kibana, you’ll point it to your Elasticsearch instance in /etc/kibana/kibana.yml.
Ingesting Nginx Logs with Filebeat
On your web server (which could be the same or a different machine), you’ll install Filebeat. Filebeat is configured via a YAML file, typically /etc/filebeat/filebeat.yml. You can enable its built-in Nginx module, which comes with pre-configured paths and dashboards, or define the inputs manually.
# Example /etc/filebeat/filebeat.yml configuration
# This setup is ideal for monitoring services in a Docker Linux news environment
# or on a traditional Linux server running Nginx or Apache.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log
# Assign fields to identify the log source
fields:
log_type: nginx_access
fields_under_root: true
# You can configure processors to add metadata, like Docker or Kubernetes info
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
# Output to Logstash for further parsing and enrichment
output.logstash:
hosts: ["your-logstash-server:5044"]
# Or, for simpler setups, output directly to Elasticsearch
# output.elasticsearch:
# hosts: ["your-elasticsearch-server:9200"]Parsing Logs with Logstash Grok Filters
While Filebeat can send logs directly to Elasticsearch, routing them through Logstash allows for powerful server-side parsing. Grok is the filter of choice for this. It uses a library of predefined patterns to extract structured fields from log messages. For an Nginx access log, a grok filter can break down the raw string into fields like clientip, request, response, and bytes.
# Example Logstash filter configuration for parsing Nginx access logs
input {
# Listen for events from Filebeat
beats {
port => 5044
}
}
filter {
# Only apply this filter to logs we've tagged as nginx_access in Filebeat
if [log_type] == "nginx_access" {
grok {
# The COMBINEDAPACHELOG pattern is a built-in pattern that matches
# the default Nginx and Apache access log format.
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
# Use the geoip filter to add geographical data based on the client IP
geoip {
source => "clientip"
}
# Use the useragent filter to parse the user agent string
useragent {
source => "agent"
target => "user_agent"
}
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}With this pipeline, your raw Nginx logs are transformed into rich, structured JSON documents in Elasticsearch, ready for analysis in Kibana. You can now build dashboards to track 404 errors, monitor response times, and visualize the geographic location of your users.
Beyond Basic Logging: Advanced ELK Stack Use Cases
The ELK Stack’s capabilities extend far beyond simple log aggregation. It’s a foundational tool for full-stack observability, security analytics, and more.
Monitoring Containerized Environments: Docker and Kubernetes
Logging in ephemeral environments like those managed by Docker or Kubernetes presents a unique challenge. The latest Kubernetes Linux news often focuses on observability. Filebeat’s autodiscover feature is designed for this. It can listen to Docker or Kubernetes API events and automatically start monitoring logs from new containers as they are created, enriching the logs with container and pod metadata. This ensures that you capture logs from every part of your application without manual configuration.
Application Performance Monitoring (APM)
The Elastic Stack includes a powerful APM component. By instrumenting your application code with an Elastic APM agent, you can send detailed performance metrics and transaction traces to Elasticsearch. This allows developers to pinpoint bottlenecks, identify slow database queries, and track errors in real-time. This is highly relevant for Python Linux news and other development communities, as agents are available for most popular languages.
# Example of a simple Python Flask application with Elastic APM
# This demonstrates how easily you can integrate APM into your Linux development workflow.
from flask import Flask
from elasticapm.contrib.flask import ElasticAPM
app = Flask(__name__)
# Configure the Elastic APM agent
app.config['ELASTIC_APM'] = {
'SERVICE_NAME': 'my-flask-app',
'SECRET_TOKEN': '', # Use if APM Server requires a token
'SERVER_URL': 'http://localhost:8200', # Your APM Server URL
'ENVIRONMENT': 'production',
}
apm = ElasticAPM(app)
@app.route('/')
def hello_world():
# This transaction will be captured by the APM agent
return 'Hello, World!'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)Optimizing Your ELK Stack for Performance and Scalability
As your data volume grows, you’ll need to optimize your ELK Stack to maintain performance. Following best practices is key for any serious deployment and is a constant topic in Linux administration news.
Common Pitfalls to Avoid
- Ignoring Data Retention: Elasticsearch indices will grow forever if not managed. This can lead to performance degradation and excessive storage costs.
- Not Securing the Stack: By default, the stack has minimal security. Failing to enable authentication, encryption (TLS), and role-based access control (RBAC) is a major security risk.
- Over-parsing in Logstash: Complex grok patterns can be CPU-intensive. It’s often better to perform parsing at the edge using Filebeat processors or Ingest Node pipelines in Elasticsearch where possible.
Performance Tuning and Best Practices
The most critical practice for managing data at scale is using Index Lifecycle Management (ILM). ILM allows you to automate the lifecycle of your indices, moving them through different data tiers (hot, warm, cold) and eventually deleting them. This is essential for managing storage and maintaining query performance.
# Example of creating an ILM policy using the Elasticsearch REST API via curl
# This is a common task for Linux DevOps automation using tools like Ansible or shell scripts.
curl -X PUT "localhost:9200/_ilm/policy/my_log_policy" -H 'Content-Type: application/json' -d'
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"rollover": {
"max_size": "50gb",
"max_age": "30d"
}
}
},
"warm": {
"min_age": "30d",
"actions": {
"shrink": {
"number_of_shards": 1
},
"forcemerge": {
"max_num_segments": 1
}
}
},
"cold": {
"min_age": "90d",
"actions": {
"freeze": {}
}
},
"delete": {
"min_age": "365d",
"actions": {
"delete": {}
}
}
}
}
}
'This policy automatically rolls over indices when they reach 50GB or 30 days, moves them to less performant (and cheaper) storage tiers over time, and finally deletes them after a year. This simple automation is a cornerstone of a healthy, scalable ELK deployment.
Conclusion
The ELK Stack provides an incredibly powerful and scalable solution for the complex challenge of modern log management on Linux. By centralizing logs from across your entire infrastructure—from bare-metal servers running Rocky Linux or AlmaLinux to complex Kubernetes clusters—you gain unprecedented visibility. The journey from raw log files to actionable insights involves understanding the roles of Elasticsearch, Logstash, Kibana, and Beats, implementing a robust data pipeline, and applying best practices for performance and security.
The real power of the stack is unlocked when you move beyond basic log viewing and start building dashboards for performance monitoring, creating alerts for security events, and integrating APM data for full-stack observability. As the worlds of Linux server news and cloud-native development continue to evolve, the ability to effectively analyze machine-generated data is no longer a luxury but a necessity. The Elastic Stack provides the open-source foundation to build that capability, turning the noise of your logs into a clear signal that drives better operational decisions.


